
【新智元导读】老黄GTC重心展示的PD分离技艺为何成兵家必争之地?UCSD全华东说念主团队力作,立异性地冷漠预填充-解码分离技艺。在严格的蔓延拘谨下,比较现存开首进的就业系统,可竣事高达4.48倍的灵验产出率或10.2倍更严格的SLO达成率。
现时,PD分离还是成为兵家必争之地。
前有Mooncake/DeepSeek等公司罗致这种技艺来优化大模子的推理就业,后有Nvidia/PyTorch基于该技艺孵化下一代LLM就业系统。
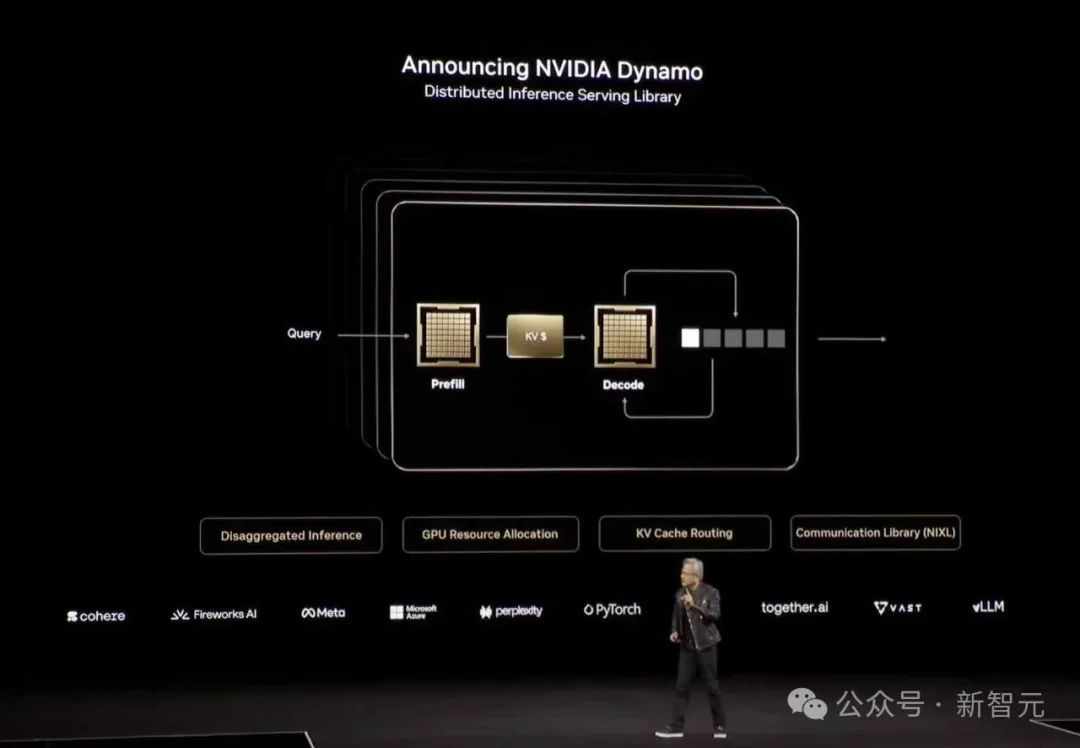
以致最近,黄仁勋也在2025 GTC的舞台上提到了PD分离(Prefill-Decode Disaggregation)技艺,进一步证明了这一技艺赢得的无为护理。
客岁,来自UCSD的一个华东说念主团队发布的一篇博客,就深刻瓦解了这一技艺的旨趣和它的应用场景。

如今,大言语模子应用有着不同的蔓延需求。
举例,聊天机器东说念主需要快速响应(比如低于0.2秒),而解码速率不错较为适中,仅需与东说念主类阅读速率相匹配;代码补全则要求快速生成,以便及时提供代码建议。
著作中展示了现存的优化隐约量的就业系统,在蔓延圭臬下并不睬思。
作家提议使用「灵验隐约量」(goodput)看成大模子就业性能的改良揣摸圭臬,它不仅护理每秒完成肯求的数目,而且适应就业级标的(SLO),更好地均衡本钱和用户体验。
为了晋升灵验隐约量,著作冷漠了「预填充-解码分离」(prefill-decode disaggregation),行将预填充妥协码分拨到不同的GPU上。
通过这个次序,作家搭建了一个系统原型DistServe,在保执严格的蔓延拘谨下,达到了比现存系统向上4.48倍的灵验隐约量,或者10.2倍更严格的SLO。
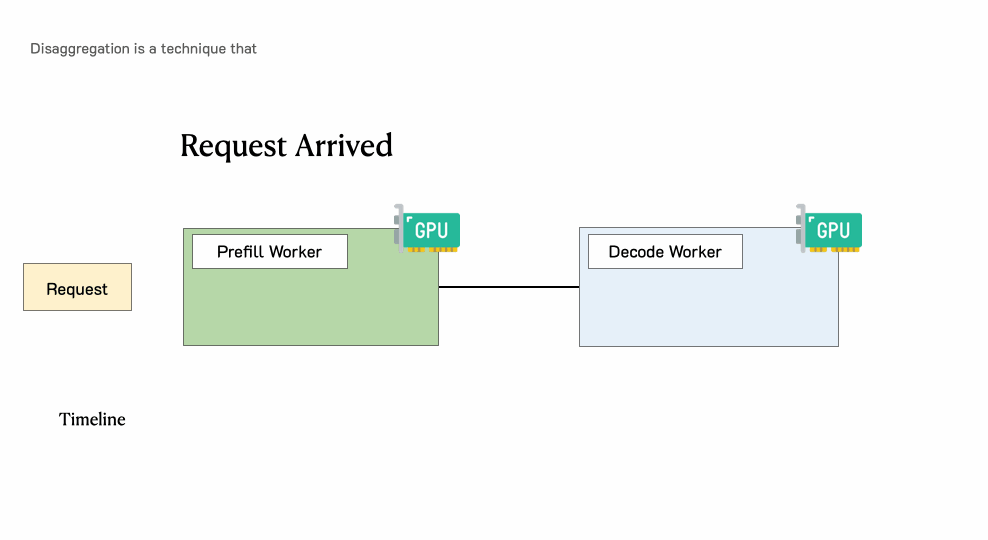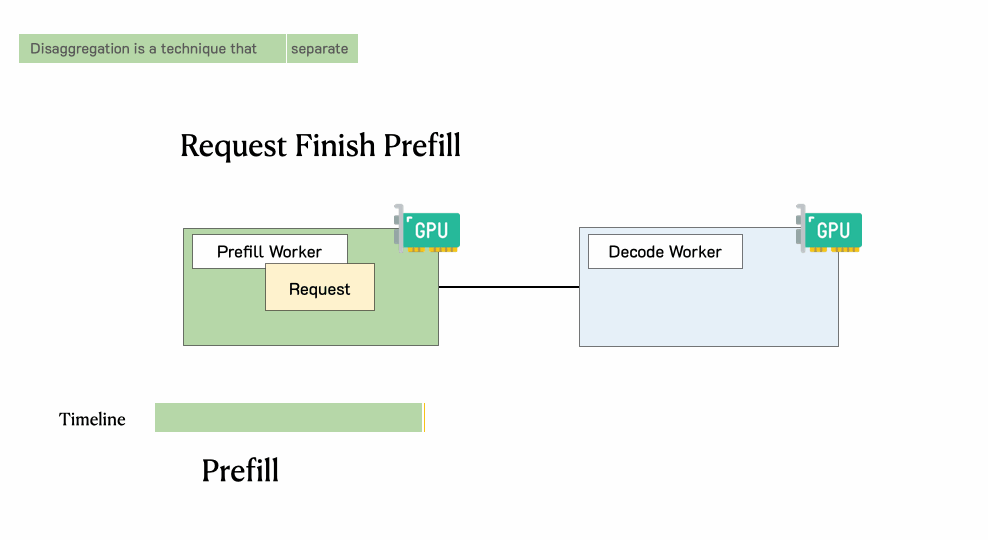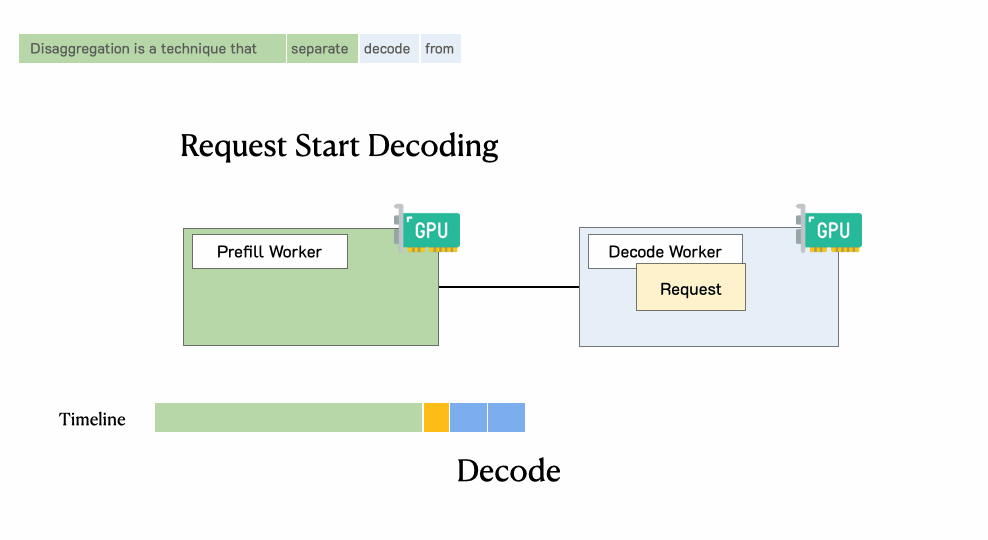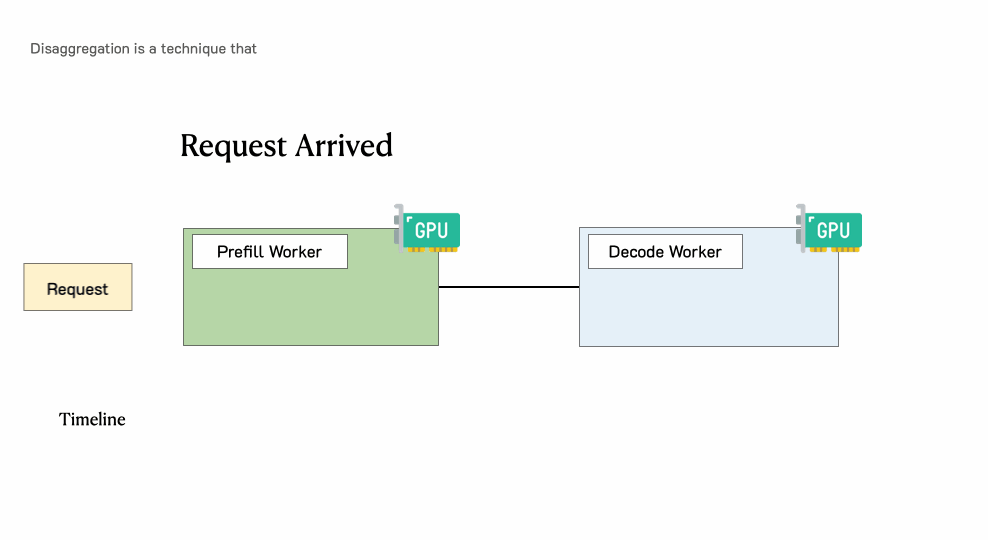
一个肯求通过一个具有分离预填充妥协码的LLM就业引擎
隐约量与灵验隐约量
LLM正在更正行业对AI的应用,但LLM就业本钱仍然很高。
为了缩小本钱,好多公司专注于晋升LLM系统的隐约量,即每秒处理的肯求数(rps),看成每个肯求本钱($/req)的替代缱绻。
大多数流行的LLM就业引擎,如vLLM和TensorRT-LLM,齐用隐约量来揣摸性能。
关联词,本体应用对蔓延的要求各不沟通,因此就业级标的(SLO)也不同。常见的SLO包括:
初次token蔓延(TTFT):测量LLM生成第一个token的时候
每个输出token的时候(TPOT):测量两个连合生成的token之间的平均蔓延
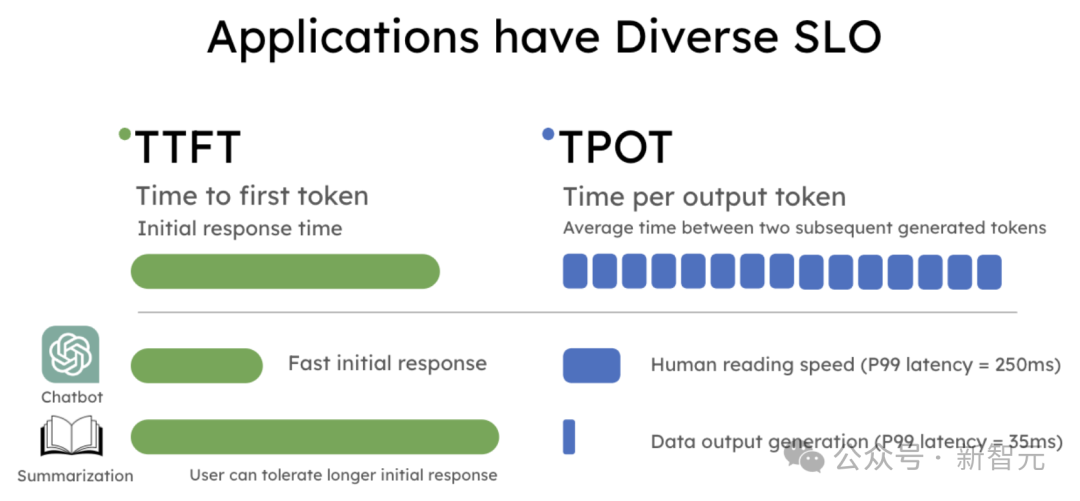
应用表率有着各种的SLO要求
隐约量只护理处理的肯求或token数,却忽视了这些蔓延需求。作家引入了灵验隐约量(goodput),它揣摸每秒完成的适应SLO的肯求数(同期知足TTFT和TPOT要求)。这比隐约量更能反应就业质地,因为它辩论了本钱和用户体验。
那么,到底什么是灵验隐约量?假定一个应用要求90%的肯求TTFT小于200毫秒,TPOT小于50毫秒,那么灵验隐约量即是每秒能完成的最大肯求数,且至少90%的肯求同期知足这两个条目。
一个高隐约量的应用可能有低的灵验隐约量。诚然隐约量是10个肯求每秒,但因为蔓延拘谨,唯有3个肯求适应SLO,最终的灵验隐约量唯有每秒3个肯求。不错思象,尽管这种系统的隐约量很高,但它的用户就业将很差。
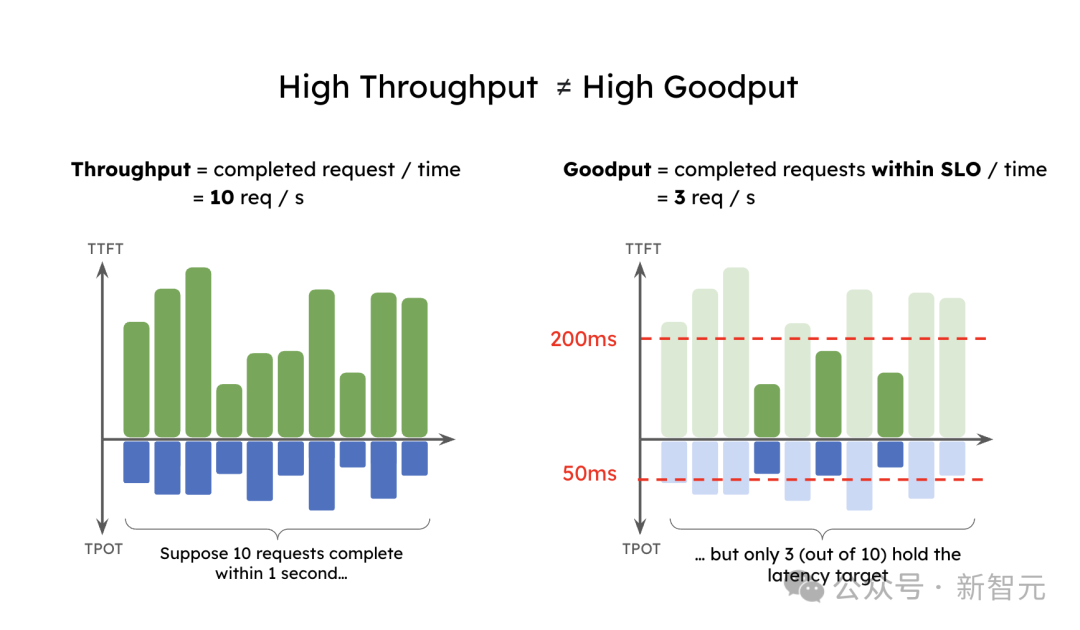
高隐约量≠高灵验隐约量
以下是在本末节中引入的术语:
灵验隐约量:揣摸LLM就业系统服从的缱绻,辩论了本钱和用户舒心度。它界说为每秒系统不错完成的肯求数目,同期知足指定的就业级标的(SLO)。
隐约量:LLM就业系统每秒处理的已完成肯求数目。
就业级标的(SLO):LLM就业系统必须知足的标的,以提供令东说念主舒心的用户体验。常见的SLO包括初次token蔓延(TTFT)、每个输出token时候(TPOT)、端到端蔓延(E2E)和指数加权平均(EMA)蔓延。
预填充:LLM推理的第一阶段,处理通盘输入token,填充KV缓存,并生成第一个输出token。
解码:随后的阶段,通过自总结形态生成token,直到完成。
初次token蔓延(TTFT):LLM就业系统响应用户肯求时,生成第一个token所需的时候。
每个输出token的时候(TPOT):LLM就业系统响应用户肯求时,生成后续token所需的平均时候。
为什么现存系统无法竣事高灵验隐约量?
在深刻分析之前,需要追忆一下LLM就业肯求的历程。下图展示了这个过程:肯求过问LLM推理引擎,系管辖先处理用户输入生成的第一个token(预填充),然后通过自总结生成后续token(解码)。一个肯求频繁包括一个预填充身手和多个解码身手,直到生成完成。
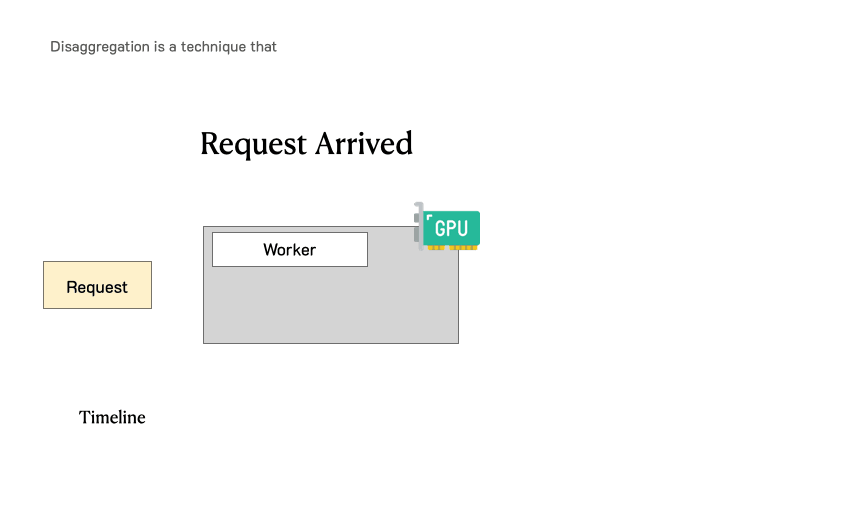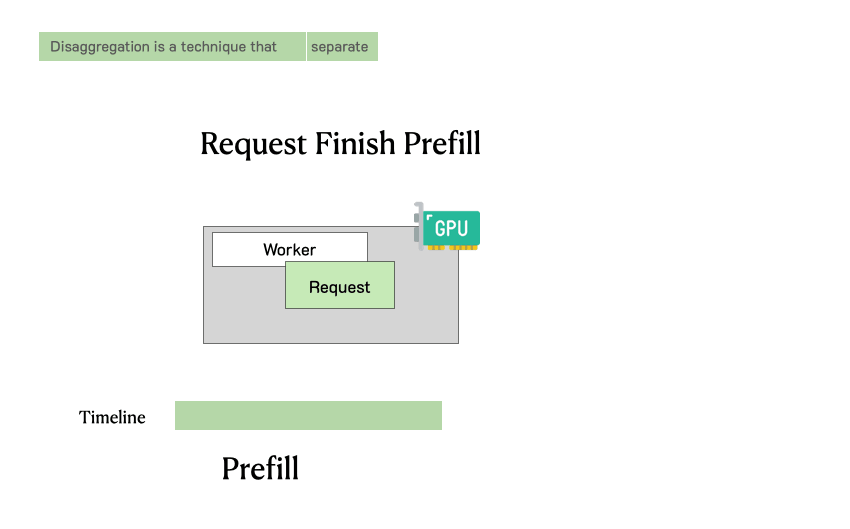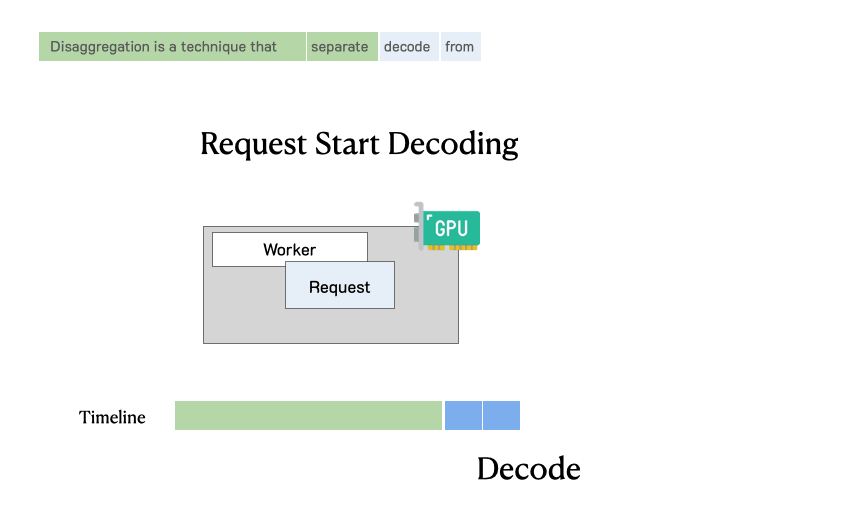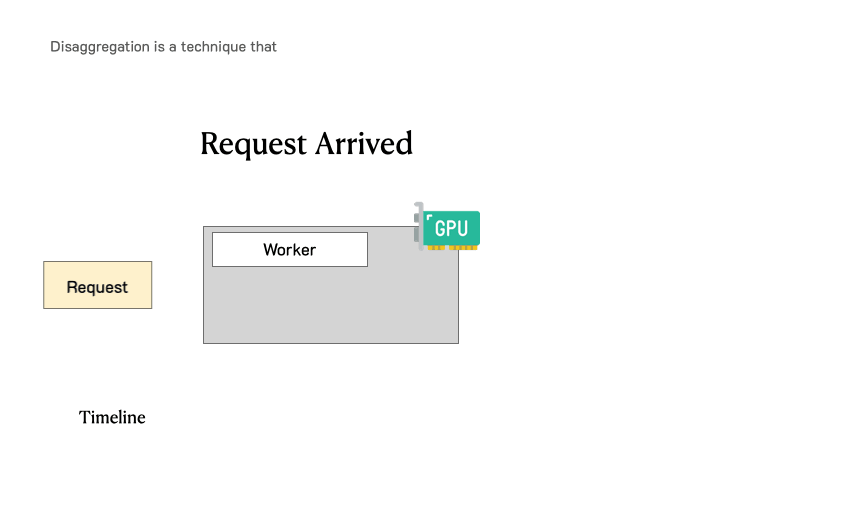
传统LLM就业系统中肯求的处理过程
LLM就业系统频繁将预填充妥协码通盘批处理,使用迭代调理或连合批处理技艺,使GPU能尽量大批量处理,从而提高隐约量(每秒token数),vLLM和TensorRT-LLM等系统齐无为罗致这一次序。
关联词,预填充妥协码在筹办上有颠倒不同的特色。
预填充颠倒依赖筹办,意味着即使是一个小批量的预填充,或者只是是一个满盈长的预填充,也会赶紧饱和GPU筹办资源。
另一方面,解码需要更大的批量来达到筹办瓶颈,且更容易受到GPU内存带宽死心的影响。
不外,预填充妥协码在筹办上互异很大:预填充筹办密集型,容易赶紧饱和GPU;而解码则需要更大批量智商达到筹办瓶颈,同期也更受GPU内存带宽的死心。
由于它们的筹办模式和SLO标的互异广宽,将这两者通盘处理并不有意于优化灵验隐约量,原因有二:
预填充妥协码之间会相互过问,导致性能下落
预填充妥协码的资源分拨及并行计策会相互耦合,难以优化
预填充妥协码的过问
下图展示了预填充妥协码之间的过问。
左:把两个肯求批量到一个GPU,收尾看到解码(R1)蔓延显贵增多,预填充(R2)蔓延略略飞腾。
右:踏实肯求流中,每次解码碰到预填充肯求时就会被「卡住」,解码蔓延因此不测增多。
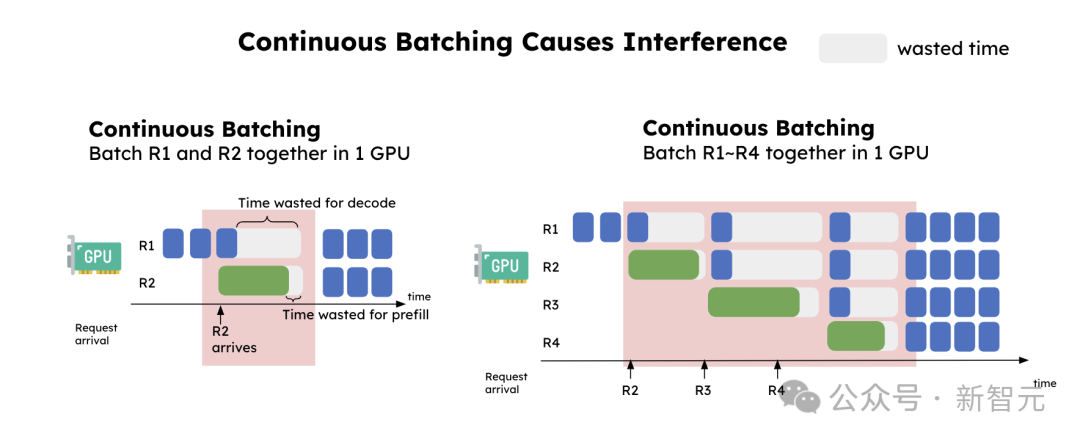
连合批处理导致的过问
这种过问导致下图中展示的情况:为了知足TTFT和TPOT的SLO,系统必须过度成就资源以知足蔓延标的,尤其当某个SLO突出严格时。
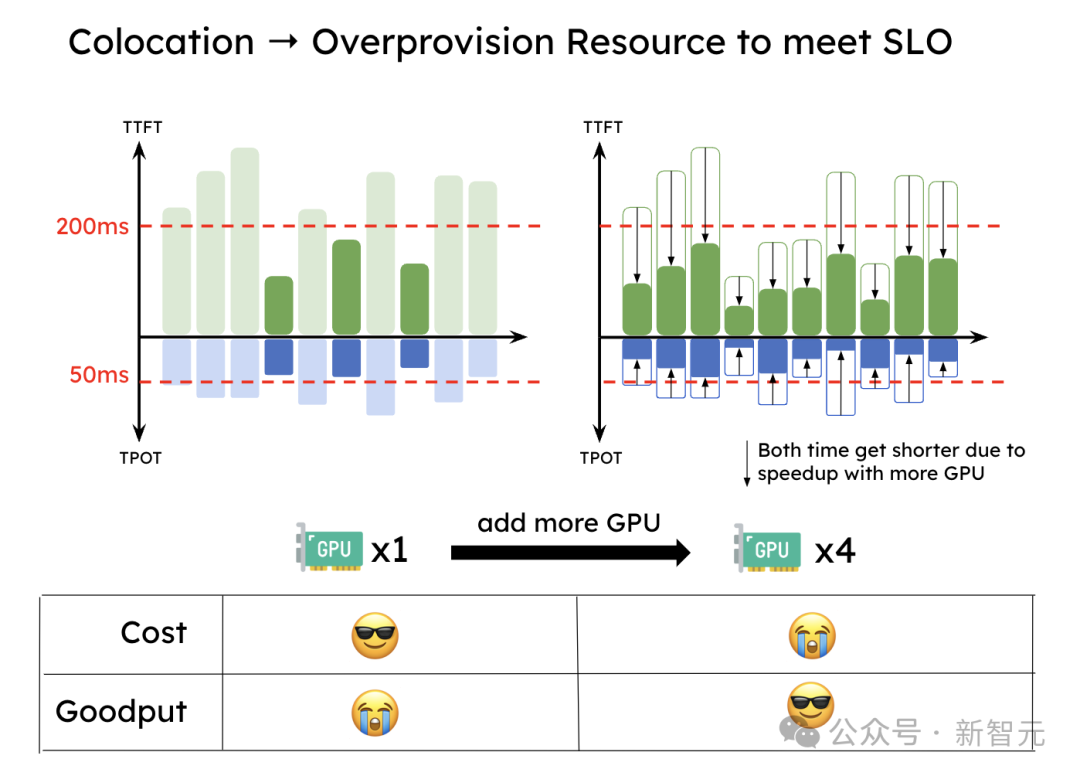
为了知足SLO,预填充妥协码共同处理的系统需要过度成就资源
此外,预填充妥协码的资源分拨和并行计策是耦合的。由于筹办模式和蔓延标的不同,最优的并行计策也不雷同。
比如,当TTFT要求严格时,预填充阶段恰当用张量并行(TP)来知足紧凑的蔓延标的,而解码则更倾向于数据并行或活水线并行来晋升隐约量。
分离预填充妥协码
直观很浅易:将预填充(Prefill)妥协码(Decode)分拨到不同的GPU,并为每个阶段定制并行计策。
这当然料理了上头提到的两个问题:
预填充妥协码之间莫得过问,使得两个阶段齐不错更快完成,并更容易知足各自的SLO(就业水平标的)
资源分拨和并行计策解耦,优化不错针对预填充妥协码差异进行
下图展示了在这种分离系统中肯求的处理形态。
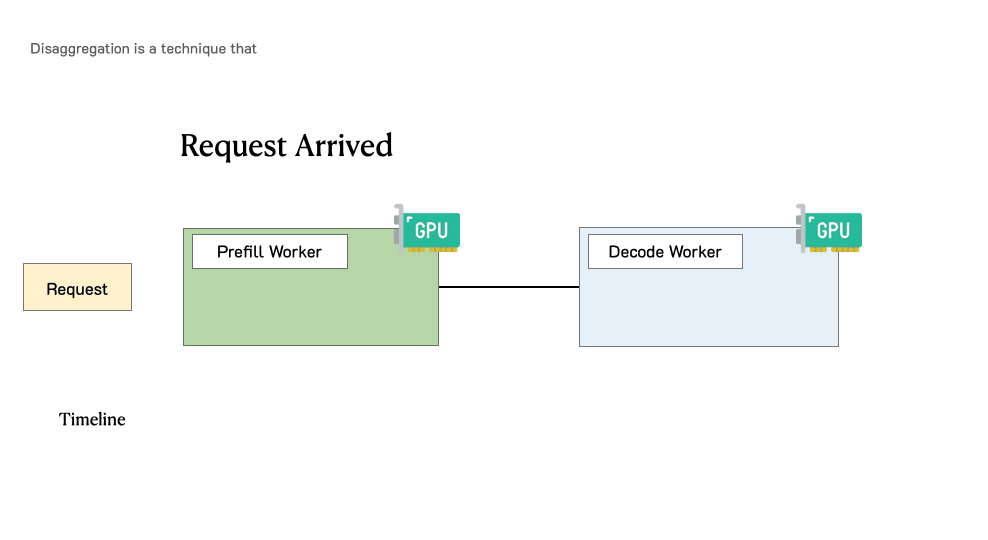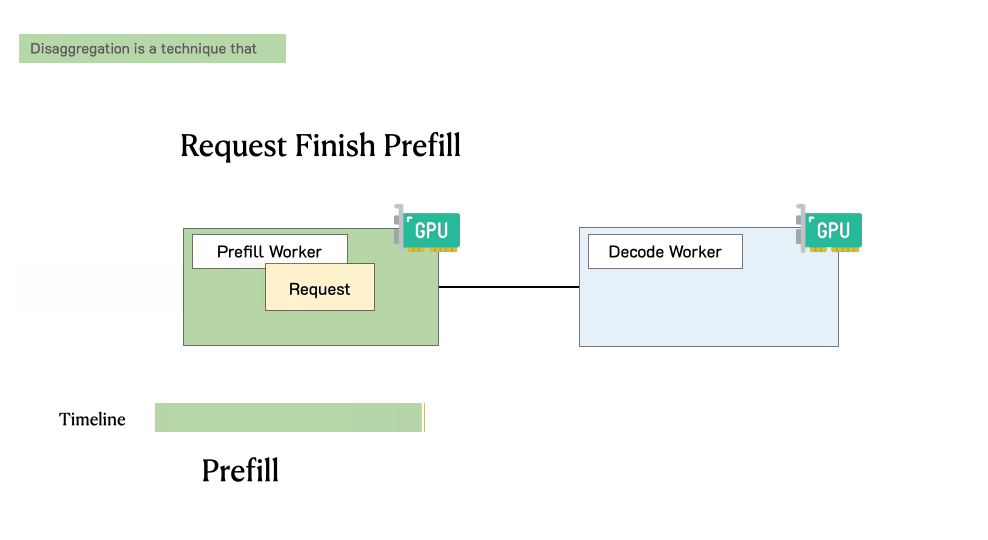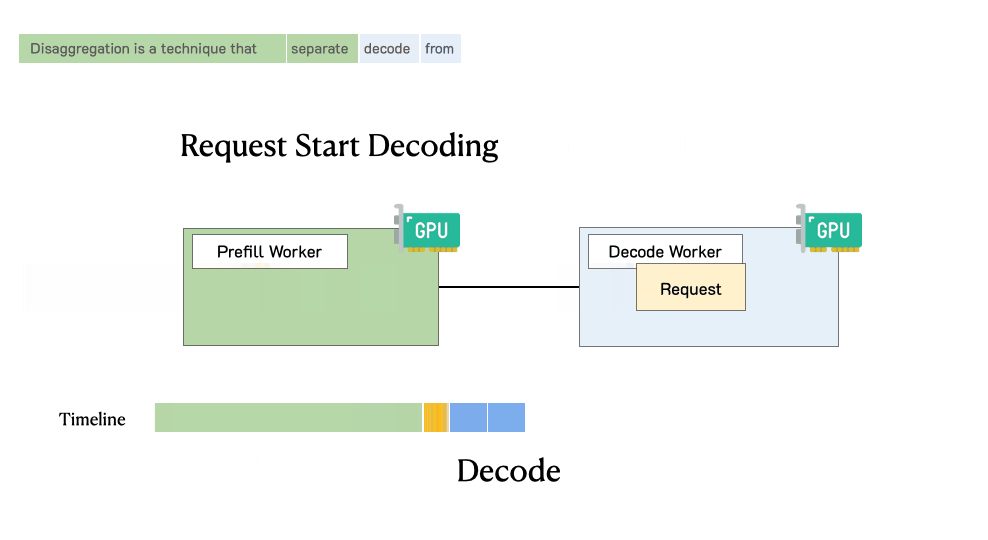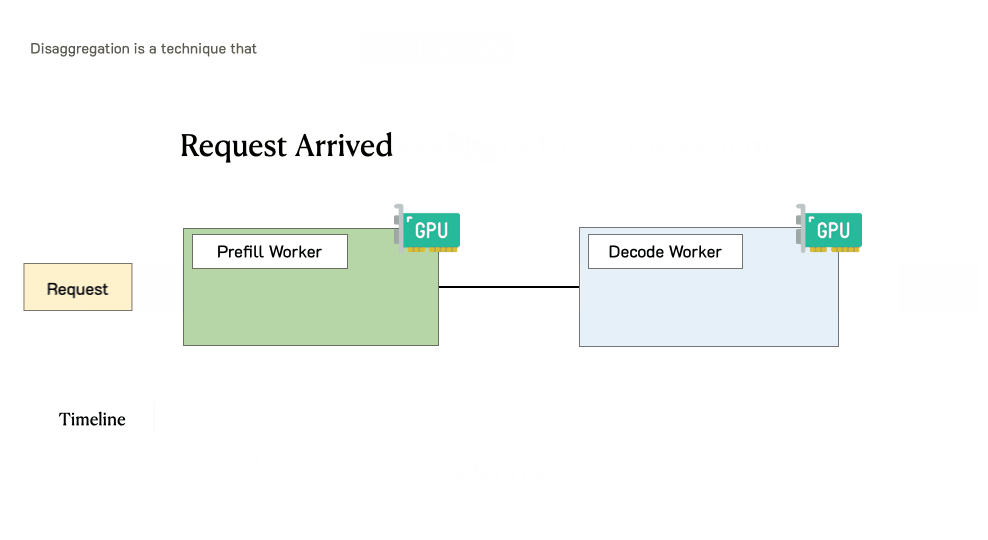
预填充/解码分离时肯求的处理过程
当肯求到达系统时:
领先过问预填充职责节点并完成预填充阶段
然后,系统将其中间状况(主如若KV缓存)迁徙到解码职责节点,并进行多个解码身手以生成后续token
肯求在生成完成后离开系统
通过一个浅易的实验,即可考据Prefill-Decode分离的效率。
在单个A100-80GB GPU上运转一个13B的LLM,使用一个输入长度为512、输出长度为64的合成职责负载,并假定肯求按泊松散播到达。
迟缓增多肯求速率(x轴),并测量这两种蔓延(P90 TTFT和P90 TPOT,y轴)中的变化。
假定将SLO确立为P90 TTFT小于0.4秒,P90 TPOT小于0.04秒,作家不雅察到,现存系统使用1个GPU时,大致赞成3个rps(Request rate per second),而TPOT则赞成1.6个rps。
由于需要同期知足这两个拘谨,现存共同处理系统的灵验隐约量为:灵验隐约量(同期知足) = min(3, 1.6) = 1.6 rps(每个GPU)。
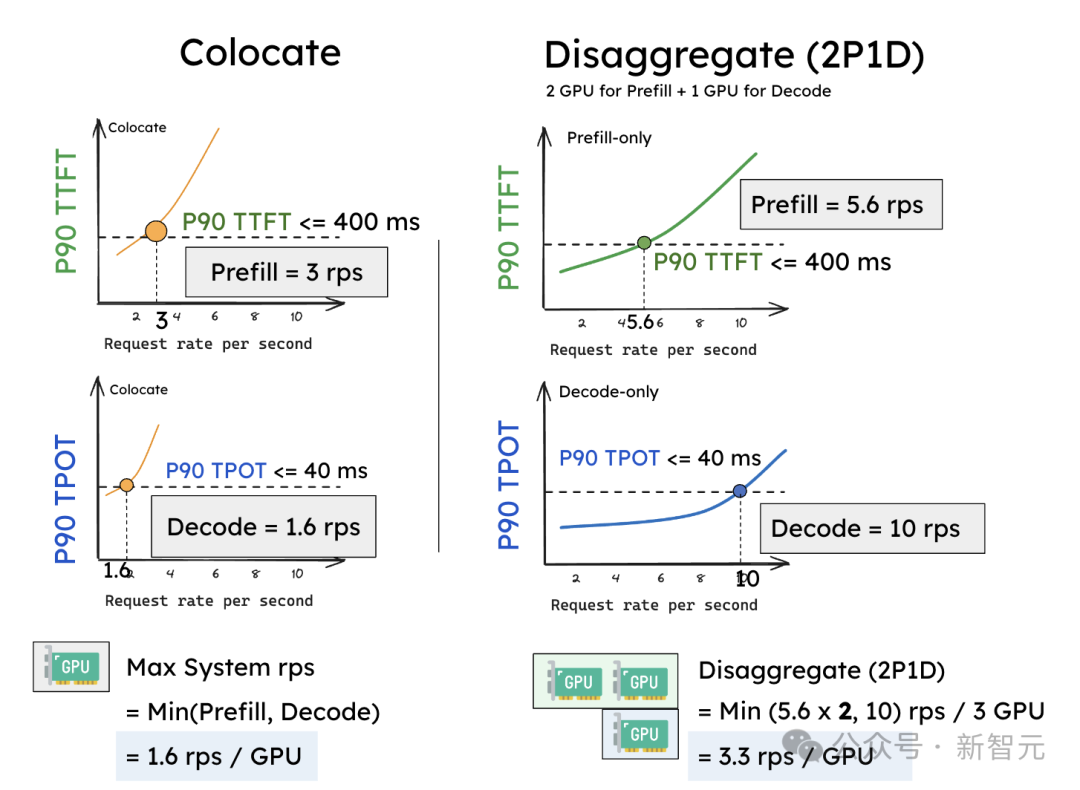
共同处理(a)相较于分离(b),后者在为预填充分拨2个GPU、为解码分拨1个GPU(2P1D)时更具活泼性
分离后,性能显贵晋升。
预填充职责节点妥协码职责节点在仅处理单个阶段时,不错差异达到比之前更好的rps——预填充职责节点大致不错达到5.6 rps,解码职责节点大致不错达到10 rps。
更进攻的是,现时咱们不错活泼地分拨2个预填充职责节点与1个解码职责节点(记作2P1D),系数使用3个GPU。此时的灵验隐约量变为:
灵验隐约量(2P1D) = min(5.6 x 2, 10) = 10 reqs/s / 3 GPUs ≈ 3.3 reqs/s(平均每个GPU)。
这个实验标明,浅易的分离次序在莫得任何并行化的情况下就能竣事2倍的灵验隐约量(3.3rps VS 1.6rps)。
特殊的公正是,预填充与解码的分离还好像为每个阶段采取最好的并行计策来优化灵验隐约量(作家称之为「定制并行tailored parallelism」)。
KV缓存传输
分离的一个代价是需要在预填充妥协码GPU之间传输中间状况(即KV缓存)。
乍一看,KV缓存是LLM推理中一个大的内存支出,而在GPU之间传输KV缓存似乎是一个瓶颈。
但相背,通过合理的摈弃,KV缓存传输的支出不错被灵验地最小化,低至小于一个解码身手的时候,这获利至今天高速的集聚技艺,如NVLink和PCI-e 5.0。
为了考据这少量,假定有8通说念PCIe 5.0 x 16(每个链路64GB/s)看成GPU之间的节点内集聚。
给定一个2048token的肯求,不错估算在就业OPT-175B(OPT,即Open Pre-trained Transformer由Meta AI开辟)时,传输KV缓存的蔓延为:
蔓延 = 2048token *(4.5 MB/token)/(64GB/s * 8) = 17.6毫秒
这个蔓延小于OPT-175B的单个解码身手的时候(约30-50毫秒,使用A100)。
关于更大的模子、更长的序列或更先进的集聚(举例,具有600GB/s带宽的A100-NVLink),如下图所示,KV缓存传输的比较支出与单个解码身手比较变得愈加微不及说念。
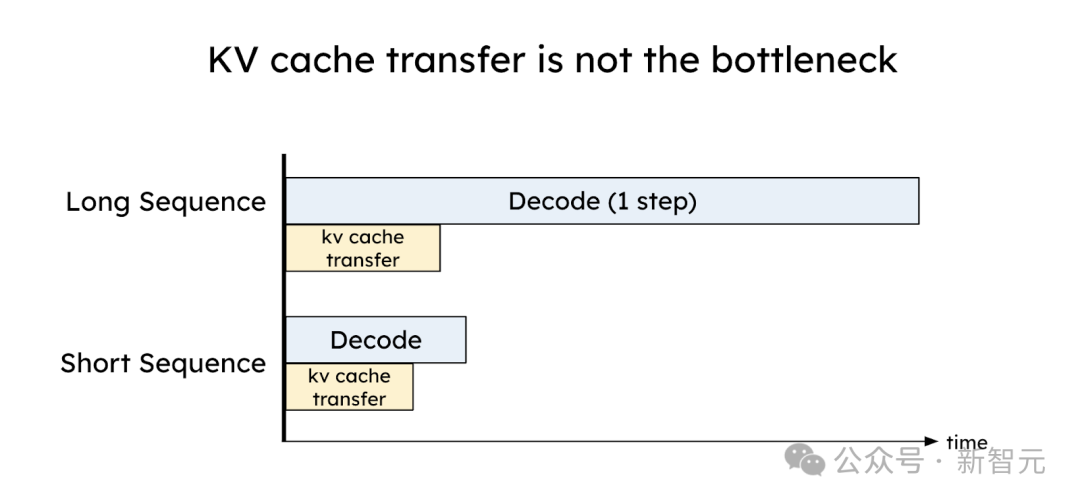
KV缓存传输支出不错被灵验最小化,低于一个解码身手的时候
经心摈弃预填充妥协码职责节点以应用高带宽集聚,不错灵验地掩饰KV缓存传输的支出。
DistServe:评估分离的效率
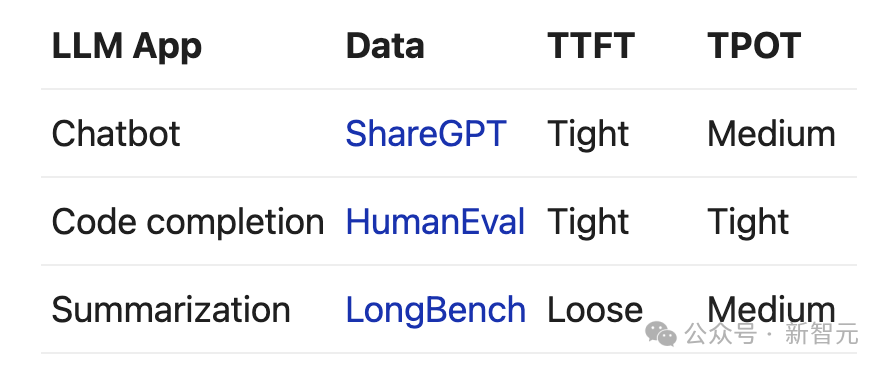
作家在一个名为DistServe的系统原型中竣事了所冷漠的技艺,并在三个具有不同蔓延拘谨的职责负载和数据集上与现存系统进行了比较:聊天机器东说念主、代码补全和摘录,注释信息见下表。
下图展示了DistServe与vLLM的对比收尾:
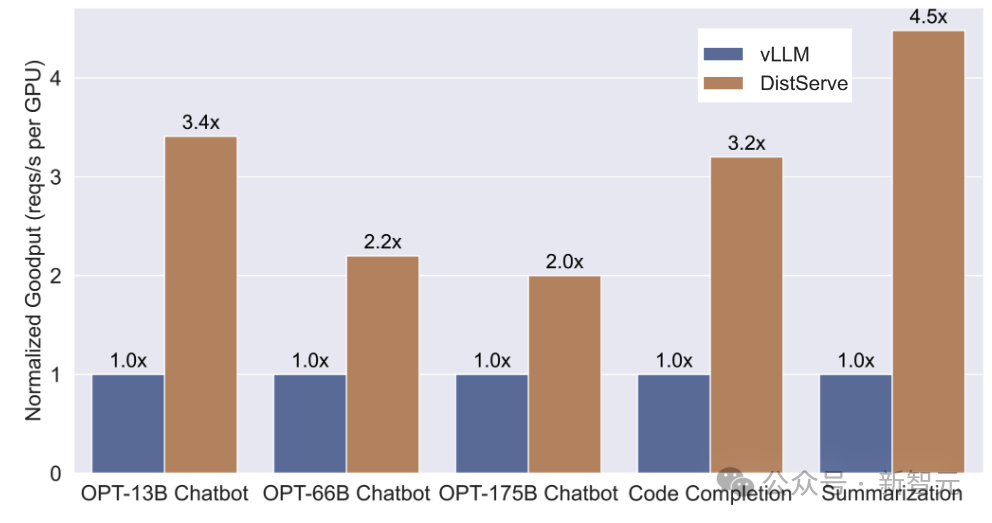
在各种数据集上评估DistServe与vLLM的发扬
聊天机器东说念主:DistServe的灵验隐约量比vLLM高2.0倍到3.41倍。
代码补全:DistServe的灵验隐约量比vLLM高3.2倍,况且SLO比vLLM严格1.5倍。看成及时编码助手,代码补全任务比聊天机器东说念主要求更低的TTFT,这使得两个系统最终齐受到TTFT要求的死心。关联词,通过摒除解码任务的过问,并为预填充定制张量并行计策,DistServe减少了预填充当务的平均蔓延,从而知足更多肯求的TTFT要求。
摘录:DistServe的灵验隐约量比vLLM高4.48倍,况且SLO比vLLM严格10.2倍。如预期的那样,由于vLLM将预填充妥协码放在通盘,它在解码阶段的延缓更大,未能知足TPOT要求。
团队成员先容
以上商讨出自加州大学圣地亚哥分校的Hao AI实验室,全部来自于华东说念主商讨者。

Junda Chen

2023年秋季入学的筹办机科学博士生。商讨兴味:高效的LLM就业系统、推理系统和算法。
Yinmin Zhong

北京大学筹办机系统商讨组的别称三年纪博士生,导师是金鑫。在此之前,在北京大学赢得了筹办机科学学士学位。对构建高效的系统来测验和提供深度学习模子有无为的兴味,现时主要护理大言语模子。
Hao Zhang

加州大学圣地亚哥分校筹办机科学与工程系的助理阐述。在UCSD指令Hao AI实验室现金巴黎人娱乐城app平台,对假想遒劲、高效和安全的机器学习模子和算法,以及构建可彭胀、实用的散播式系统以赞成履行天下的机器学习职责负载感兴味。